Think of this "tutorial" as an autobiography of a programmer, and you may find it easier to read.
It is not yet finished... but there is lots of useful information in the material that is done so far.
If you choose to read thorough it, you will get the experience of sitting at my elbow as I work through the development of an application. This tutorial is not like most of the other tutorials on this site.... but it will, I hope, help you become a stronger programmer.
"How To..." style tutorials have their place... I benefit from the works of others often! But "How To" is not the whole story. Let me make an analogy? Suppose you wanted to become a composer of music. (Programming is remarkably like that, I continue to believe more and more firmly, years after the thought first struck me.) You can take lessons in counterpoint. You can read books about how the different modes (major, minor, dorian, etc.) "work". You must learn notation. But can you compose yet? Not necessarily! If you look at a finished musical score (or program), you can look over all it's parts, see how they work... but that still doesn't tell you how the craftsman got from blank sheet (screen) to the product. This "tutorial" lets you follow the journey of one project. (It does give you a few "How To's" and Important Concepts along the way.)
It all started harmlessly enough... about ten years ago. (That "incubation period", while longer than most!, is sometimes an important element in getting an application written well.) I invest in the stock market. What I am about to describe is not something that makes a good reason to buy or sell a stock... in and of itself... but it can draw your attention to things that may subsequently pass all the tests.
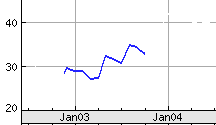
Suppose you had looked at Dow Chemical back in September 2003 when its stock price history was....
("Thank you, Yahoo" for that graph, by the way. Farther down the page you will find a link to the subsequent Dow Chemical history so you can see the "fun" Dow Chemical investors had in the months following this opportunity(?) to buy....)
It does look like Dow Chemical might have been underpriced at that time, doesn't it? Should we have bought it then, to sell later at a higher price? Were good times "just around the corner"?
I thought it would be nice if I could draw lines on such things, lines like....
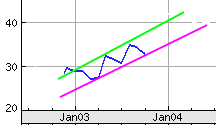
... and then at any time, either call up the charts, with my lines (and possibly revise the lines) or, more importantly, get the computer to look though all of my charts-with-lines and work out things like...
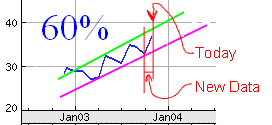
... and alert me to things where the price had moved close to either line. Note that the graph above simulates looking at Dow Chemical again, on a date after the date on which we drew the previous graphs. The new prices data is included on the graph. (The red labels "Today", and "New Data" would not be on the output I envision; they are just notes to help you follow this description.) The blue "60%" would tell me that, for the date shown, the day's price is 60% of the way from the lowest I thought possible to the highest I thought possible.... i.e., if my lines are right, we're getting up to prices where we might consider selling. (Remember I said that this data would never be suffiecient unto itself... it would only be good for altering you to things you ought to look into.) Note that the 60% is calculated from figures that change every day.
If such a system were built, it wouldn't just be for deciding when to buy or sell. It would be a useful way of arranging for the computer to alert you to reconsider a given stock because its price had strayed outside of the area between the lines, an area that you can define, and you may choose to define as "if it is in this area, I'm not worried about this stock. I will be surprised if it strays..." And the last thing investors like is surprises! So when they arise, the prudent investor investigates. Mind you... stock market investors don't mind other buyers and sellers getting surprises!
Well... a "simple" enough idea! Building the system to deliver the graphs may be less than simple. I hope maybe you'll take the trip through the rest of this, if only to increase your respect for what programmers do, and to help you appreciate all that the programs in your computer do for you. What I've described is much less complex than a run of the mill word processor or email program.
By the way, ("buy" the way?)... what happened to people who bought Dow Chemical at $34/ share in September 2003? Yahoo will tell you!
That brings us to the end of the material which will be of interest to casual readers. However, if they are feeling kind, it would be appreciated if they were to jump down to the "ads from sponsor" at the bottom of the page.
The rest of this is still in draft form, and will only interest people who want to build databases, write programs.
Now we turn to what would be needed for such an application. It may seem that I am taking an elephant gun to a mouse in what follows. I promise you, though, that everything I will describe has a purpose. If such an application were built (I've started it!), while bits of what follow might not be needed immediately, they would be part of the foundation of everything that might one day be needed. The start I've made should, if I've got it right, lead a long way without hitting dead ends. It should create a robust application- one that resists the entry of bad data. One that is scaleable (i.e. it not only works for a few charts, but still works when you are following scores of companies.)
Many of the considerations that are going into the development of this application would apply to the development of applications for other fields. Don't stop reading just because you aren't a stock market investor or trader.
One sad bit of news: The ultimate objective of this exercise is still an project for the future. I can't yet do all that I want to, but the material we're going to cover is a large part of the journey to that goal, and it is also useful in its own right.
First a quick word about the basic meaning of "datafile", and an indication of what we will be doing with datafiles.
A phonebook is a datafile in an ink- on- paper form. It is made up of many rows of information, each row having a basic form: Name, address, telephone number.
When a datafile is in a computer, if you have provided all of the tools that you might, rows ("records" in datafile parlance) of the data can be removed, new rows can be added, what's in a given record can be changed, and you can have the rows printed out in different orders, or with only those meeting certain criteria present.
Reading and writing from/ to a datafile is a little different from the loading and saving you may be used to, for instance when working on a word processed document. With anything beyond a very simple database, the computer takes care of keeping what's on the disc up to date all the time. It doesn't wait for you to "save". Usually as soon as you move on, having changed some value in some row of the database, the change you made is passed on to the hard disc.
So... enough about databases... Now we'll get down to the process of creating this application.
Having thought carefully (in more detail than I've related) about where I want to end up, I sat down with a piece of paper (literally) and drew diagrams, made lists.
I diagrammed where data would come from, where it would go. Boxes on the diagram stood for datafiles, ovals stood for the programs that acted on the datafiles. Arrows between them showed which programs wrote to, which read from which datafiles. (Some did, of course, read and write to one or more datafiles.)
I listed all of the datafiles I could anticipate. It is a Very Bad Sign if you discover that you need a datafile which you hadn't realised you'd need BEFORE you started building the application. You should have planned more carefully!
For each database, you need to decide what fields it will have. (In the example of the phonebook, the "fields" were "name", "address", "number".) You need to decide how the information in the fields will be coded. I don't mean "secret codes" here. Take the stock market example which is, after all, the subject of this. There are many times in the application that we'll need to say which stock we are talking about. How are we going to specify, say, the medical giant Pfizer? In most instances, we're going to use its "stock ticker", the "code" (or abbreviation) that the stock market uses for Pfizer: PFE. You'll learn more about this issue of "how will it be coded" from the specifics which follow.
Before turning to that, a word about "type". Be careful... here it means almost what it means in general, but we're using it a little more tightly than we do in everyday speech.
Every item of data in our databases, every field, will be of a certain "type". There are two broad sorts (I nearly said "type"!) of "type". There's text data and there's numeric data. Each has it's pros and cons. The name of a company ("Pfizer" or "PFE") will be stored as text type data. Not only will we tell the systme that anything in a stock name field will be of type text, we will tell it how long the longest entry will be. The price data is numeric type data. There are books written about the different numeric types. Again... watch out for chances to learn more about these things as we get into the project.
I'm not going to tell you everything I planned before I started. But you must realise that I had almost all of the datafiles pretty fully described, considered, before I ever started building the application. It didn't "grow" quite the way it might seem just from reading this. I "scribbled down" what I thought I'd need... which led me to realise I'd need something else, which led me to realise that the field I was going to have in the first datafile wasn't right, that it would have to be changed, which led me to realise... etc, etc. Get the idea?
Now a little digression into the topic of "good database design".
The phone book is a pretty simple "database". As described, it consists of only a single datafile.
Behind the scenes at the phone company, all sorts of things are going on. For a start, I bet they have another datafile that has the following fields (columns), with one record (row) for each time a fault is reported on a given telephone number:
Now, you might wonder why the phone company doesn't list the customer's name in this second datafile. Doing so would be a Bad Idea, because it already has the name in the other datafile. If they need the customer's name, it would be better to go over to the other datafile, search for the record with the same phone number, and access the name there. Having the name in two places wastes space and, worse, creates the possibility of Bad Data: the names could be different in the two places. (That second datafile might well want a field for "Person reporting fault, however.)
Having the name in just one place might seem to introduce compexity and complication, and it does, in some ways, but it is still a Very Good Idea for all that it does to make the data RELIABLE. Also, the person who takes reports of faults will be thankful that they don't have to type the customer's name again and again!
So: A Rule of Databases: Don't duplicate data.
Another thing that you want to build into databases whenever you can is a key. A simple key is a field which will have a different value in it for every record in the datafile. For the phonebook, the phone number could probably be a key... unless two people each had a listing for one telephone line, in which case the number couldn't be the key.
The rows can be sorted by the key... or not... or sorted according to the data in one (or more) of the other fields. Don't confuse keys with sort criteria.
Notice I said simple key earlier? Sort of suggests that more complicated keys exist, doesn't it? Fear not: the other keys aren't too complicated.
Suppose your phone book only listed the employees of a small firm. Further suppose, as almost always makes sense, that you store each person's surname in one field, and his/ her other names in a separate field. And lastly suppose that both John and Jane Smith work at the firm. You couldn't use the surname field as the key, because there are two rows with "Smith" for the surname. But a key can be made up of two or more fields. You could key the datafile on "surname + other names"... now there are no two rows with the same key. There's one with "SmithJohn" for it's key's value and one with "SmithJane"... different! So okay!
Beware when choosing key fields. While a small firm might have only one "SmithJohn", I'll bet that the phonebook for any large town has more than one. If all else fails, you can always resort to giving things otherwise meaningless numbers... but try to avoid that, when you can... but you can't, always.
A datafile! At last!
One file we're going to need in order to build the application described at the start of this is a file filled with the prices for a stock on different dates. In fact, we are going to have many such files, one for each company's price history. If you really want to have fun, fire up your database program and build these things with me as I go alone. I'm using the excellent ooBase in OpenOffice, version 2.
Even before starting ooBase, I created a folder for the project. It is called PDB058 because it is my 58th database. (The "P" harks back to Paradox, which I use for many legacy databases.)
(Note that "database" means different things in different contexts. Just Let It Go, as best you can...) My ooBase started up with the "Database Wizard", where I...
Eventually, the table wizard opened.
I then used the wizard to make a ROUGH start....
... and found myself back at the start of the Table wizard... I think this happens when you've made some mistake, specified something impossible. The wizard still had my selections intact on the first page, so I went through again... and this time, on the last page, "Next" was greyed out, and when I clicked "Finish", I went into the table design page... which is what I wanted! Go figger. Sigh. But! Onwards...
I changed the name "DateSold" to Date
I changes the name "PurchasePrice" to "PriceClose", because this field is going to hold the stock's closing price for the day. I changed the field type to "integer". (I'm going to record the prices in pennies, to make certain internal things easier. I.e. if the closing price was 58.50, i.e. a share cost $58.50, then in my database, I'll have 5850.) For more on types, see my tutorial.) Be thankful that we've gone to pricing things with decimal fractions. I spent many pre-internet days entering prices by hand, from lists written in vulgar fractions, so when I saw 58- 6/8, I had to type 58.625. Hurrah for the internet! We won't have to enter price/ volume data by hand. There are free sources of that data in online, machine readable, form.)
Add another field, name "Volume", tytpe "Integer". (Leave the choices at the bottom alone.) Click the "Save" icon, or use "File | Save"
Close the table designer.
You should be left with the main ooBase management screen... "Tables/ Queries/ Forms/ Reports" in a column at the left, two panes one above another on the right.
In the column at the left, select "Tables" if it is not already selected, and then you should see "PFEa" in the lower pane. (In these table names, use the same case for letters as I've used.... i.e. don't use, say, pfeA.) Double click on it. That should open the table for data entry
Enter the following data
(Remember we're entereing the price in cents, not dollars.) The volume is in thousands, i.e. in my hypothetical (but nearly "real" data, the close price on 1/1/2006 was $24.00 and the volume was 51,234,000.
(You can change the appearance of the data, e.g. make 1/1/06 appear as 1 Jan 2006, by clicking on the column heading, selecting "Xolumn Format", and making it what you want. It probably pays to make the date display with the month in letters because of the never ending difficulties ariding from the fact that some people put dd/mm/yy and others use mm/dd/yy
That will do for now... close the table.
From the main ooBase management screen, right click on PFEa, click copy. Right click again, this time in a neutral part of the "Tables" pane, and select "Paste". Change the name to GOOGa. Leave the "Definition and Data" radio button selected. Click "Next". Click on the double chevron ("<<") to say "I want all of the columns included in the new table." Click "Next". Don't change any type formating in the next page, just click "Create".
And do all that again to dreate a table called IBMa.
Double click on GOOGa
Change the prices ad volumes to....
I got the figures from those nice people at finance.yahoo.com)
Edit the IBMa file to make it...
Ta! Da! Our all singing, all dancing "Find the things to buy and sell" system is started!
Take a break! You've earned it... After just a few last little bits of learning about what the right words for things are and tying up loose ends.....
The tickers for those companies are PFE and IBM, so why have I added an "a"?
At any one time, a ticker, IBM, say, stands for a particular company. However, companies come and go, and tickers get recycled. As our database will cover many months, perhaps years, I am building in a way to distinguish between companys which have used a given ticker. Years ago, for instance, "S" was the ticker for Sears. Now it is the ticker for Sprint. I can have files for the prices of both, because I will call them Sa and Sb. (Ticker "T" is especially tedious, having been AT&T's ticker years ago, and being "AT&T"s ticker today... but it is a different AT&T!
Sorry... I've been a bit sloppy with a few terms, and a bit late in bringing another to your attention
"Database" is a tedious word. It gets used too many ways. I can (correctly) call the phonebook a database. I can call the information we entered about Pfizer's price a (very small!) database. I can call the whole collect of price figures (PFE's, IBM's, and GOOG's) a database. So far, these are all variations on the theme of "database is an organised collection of data".
It is also quite proper to call the program that allows you to view the data, edit it, get reports on it a "database". ooBase is a database. MySQL, Paradox and Access are other database programs.
You'll just have to infer the meaning from the context. So much for the word "database"
Forget about databases for a moment. Just think about simpler computer use, say for writing letters, or storing photos. We talk of saving a document to "a file". Typically each document, be it a letter or a photo, is stored separately. If you explore your backing store, you find separate entries for each one. This is the normal state of affairs.
Now think about your email for a moment. Ever try to look for the file holding a particular document? If you have, you will have discovered that many email programs don't use the nice simple one- document/ one- file system. (There are good reasons for this, which we won't go into here) The email program gets "clever", and stores a bunch of emails in a single file.
Now go back to thinking about collections of data on the computer. You might, quite reasonably, have thought that there would be 3 separate files for the price information for the 3 companies. Not so. And you might have thought that that would be it. Not so. Because of aspects of the ooBase work which we haven't touched on yet, there is information it needs to store in addition to the prices data we've asked it to have available for us. So there would be more than 3 files. However, it works a bit like the email program, and keeps the data for all 3 of the company's prices in one place, along with some of the information I've alluded to. If you look on your hard disc at the moment you'll find PDB058.obd and, perhaps, PDB058.lck. Don't worry about it... just be aware that things are not as simple as you might have thought they would be.
Moving on: "Table". We've seen the term, now I need to nail it down. A better name for the 3 "things" that hold price data is "table". Tables are at the heart of the sort of programs for managing data that this essay is about. Each is composed of a number of columns (Date, Price, Volume, in the case of the three tables we've discussed so far.) Those columns are the fields of the table. Each field is set up to handle data of a specific type.
The table consists of a number of rows. The term for a row is "record". Each record consists of values for each of the fields defined by the table... although a "value" might be "no value", i.e. you can sometimes leave some fields empty. When you are in the table design tool you can specify whether users are allowed to leave a particular field blank. Key fields can't be blank, for reasons that will be evident, if you think about it for a moment. (Every record's key field has to hold something not found in any other record's key field, remember? Why do we put up with this nuisance? Why do we accept not being free to do what we like? Because having a key field... with its rules... makes it easier for the people who made the program that mananges your data for you work fast and reliably.)
Note the way I've been using those terms: Table, record, field. They are fundamental to databases. I will try to use the terms accurately, and if you think about them clearly, you'll move forward more quickly
We haven't yet, and won't for a bit, meet forms. However, they are the "proper" way to work with data in tables. It is usually a Bit Risky to edit the data in a table directly... but you can certainly get away with it, especially in little projects, especially if you are careful. On the other hand, making a simple form isn't hard, and you can set one up to look just like the table if you wish to. But, for a while, that will be left as an exercise for the student.
Time for that break!
Right! Refreshed?
Cast your mind back to the telephone company database I spoke of earlier. There was the "Numbers" table... one record for each number. There was the "Faults" table.... no records for some numbers, one, or more, for others.
Our stock market database is going to have two tables in which users can, if they wish, record comments about companies. There will be a separate table of each type for each company, just as there is a separate table for each company's prices data.
One table will be for short comments, the other will be for longer comments. Any comment in the "long comments" table will be referenced from a comment in the "short comments" table. The first (short comments) table will have the following fields:
The long comments table will have the following fields:
The tables will be named by adding SC and LC to the company names.
In both tables, the date/time stamp will be used as the table's key. This means that only one comment can be made per minute, but that shouldn't be a problem.
The "code for comment type" will consist of three characters. This will be a required field, and must be filled with codes from a list that will be kept in yet another table. We'll come to what they might be in a moment. For now, I need to mention that in addition to the other codes, "mis" will be a code, to stand for "miscellaneous". That code is there to handle the cases when a comment is being made which doesn't fit an existing category. Adding categories is allowed, too.
The "flag" in the short comments table will simply hold "y" or "n". This, in fact, is a bit of a cheat... but it will save lots of time when using the database... if only "time" at the computer's level of perceiving such things. Why a cheat? We are essentially entering something twice. This was the Bad Idea we discussed earlier when we considered whether the phone company's database should have the customer's name in the "faults" database. Since the "long comments" key is the date/time of the comment, the same date/time as in the short comments table, we could, in theory, use the date/time to "see" when there was a long comment expanding on any short comment. However, this would mean checking through the "long comments" table each time we accessed a short comment. A little work to keep the "Is there a long comment" flag accurate will pay dividends.
Why two tables, one for short comments, one for long? The way ooBase (and other data management programs) deals with fields which consist of a few characters is different- and faster- from the way it deals with fields capable of more extensive text. By providing for both types of comment, we can take advantage of the advantages of the short comment when it is adequate for our needs, and fall back on the more cumbersome long comment when necessary.
Go to your ooBase again, use the table design wizard to set up PFEaSC
FieldName FieldType Length --------- --------- ------ DateTime Date/Time - CmntCd Text(fix) 3 LC Yes/No - Comment Text[var char] 50
When you've typed in the above, right click on the grey box to the left of "DateTime" and click on "primary key".
The names "CmntCd" and "LC" (for "does Long Comment exist?") are unhelpfully short... but seeing as they will be the labels for columns with data that consists of only 3 and 1 character, respectively, it seems foolish to make the name long, as it will waste horizontal space in some displays of the data.
Save what you've done, call it PFEaSC, but DON'T close the table wizard yet. Click on "File | Save As" and ALSO save what you've got as IBMaSC and GOOGaSC
Good. That's progress!
We'll leave creating the Long Comment tables until later.
Remember we said that the allowed "comment codes" would be a limited list, but one that includes "mis", for Miscellaneous? Well what better way to constrain the allowed codes that via another table!
Alter what's in the Table Design Wizard to make it....
FieldName FieldType Length --------- --------- ------ CmntCd Text(fix) 3 CmntCdExpanded Text[var char] 25
... and save that as CodesCmnt. It's only a simple little table, but it will be useful, none-the-less.
Close the table designer, double click on The CodesCmnt table and enter the following small initial selection of possible comment codes. (The code indicates the sort of comment; it isn't an abbreviated form of a comment.)
I've used lower case thoughout the comment codes because lower case letters are....
mis Miscellaneous br1 Advice of Broker1 br2 Advice of Broker2 wsj Wall St Journal article
If you cast your mind back to where all of this started, you will realise that we need some way of saying where the lines ought to be drawn on the charts.
I'm calling the "lines" the "criteria", because they are the criteria by which the investor will decide if the price is good or bad, for selling or buying.
There will, again, be a "criteria" file for each stock, and the name again will start with the stock ticker, plus the extra letter which allows for tickers being recycled. All of the criteria fikes will be distinguishable by the suffix CR, so we'll need....
Each CR file will need at least one record. It may have more than one. Each record will be the criteria selected by the user at a particular time. The records won't take much space on the hard disc, so we might has well save the complete history of the investor's ideas.
Once again, the first field will be a datetime, and will be used for the table's key. One feature that will eventually be built into the application is a way to scan all of the criteria, and bring to the user's attention any that haven't been updated for a while.
Confession! In spite of all I said earlier about planning where you are going before you start, I am a little hazy about an essential element of this whole project....but fear not, the haziness has crisp edges, and I know that I will be able to resolve the areas of indecision.
The "criteria" consist of two lines. Anything that will define those lines will do... but some ways of defining them will be better than others.
One solution would be to record two dates in the record. They would define the left and right ends of the lines. Besides those two dates, you would need four prices: The start price of the upper line, the start price of the lower line, the end price of the upper line, and the end price of the lower line.
Don't worry! I don't imaging that users are going to type all of that in by hand! A feature of the application would allow users to define and re-define the criteria just by dragging the lines around.
What I've described would "work", but might not be the best way to go. It might, for instance, be better to record the start date and the low and high prices, and then add just the slope of each of the lines. I say "might be better" because we're going to have to do calculations of where the lines are on different dates. If you have the slope, which won't change until the criteria change, those calculations are relatively easy. Why not have the slope readily available? You're only going to have to calculate and re-calculate it from the four points (if you use the scheme I described first)... each time you want to ask how today's price compares to what the lines would claim are "good" prices.
So... you see: My "haziness" is pretty well fenced in. I know where I'm going... I just haven't made some final decisions yet.
By now you may be wondering how ooBase can do all of the things I have been describing. I don't know. But I know it can manage the data that will be needed to do all that I have in mind. In a worst case scenario, I will use ooBase to manage the data, and at the end of each day, I will tell it to export files that programs written in Delphi can use to present me with my charts- with- lines. I don't think the export phase will be necessary. I'm pretty sure (another area of haziness, but with alternatives known) that I can get Delphi to look into the ooBase tables, read things from them, and even write things to them. I also know that, if you know enough, you can get ooBase to do some amazing things. I'm just not sure I'm in the mood to do the work to "know enough"... but I'm comforted by my assumption that another way to reach my destination does exist, if either of the routes I plan to use prove impassible.
For the sake of making a start, we'll assume that the second system is going to be used, and will express slope in "pennies per year". (The slope can be up (positive pennies per year) or down (negative pennies per year). Just because our units are "pennies per year" does not mean that we are assuming that our criteria will be reasonable for that long, nor does it prevent us from using the criteria for longer than a year, if they remain valid. An example of the "pennies per year" system in action: If you think that one of the criteria lines should start at, say, $50 on 1 Jan 06, and rise to $60 over the next 12 months, then, remembering that we're pricing things in pennies, you would enter the following:
1/1/06,5000,1000
Extending that to cover all of the fields needed in each CR table, and pinning down the details leads to....
FieldName FieldType --------- --------- DateTime Date/Time Conf Tiny Integer LineStart Date YHi Integer YLo Integer SlopeHi Integer SlopeLo Integer
I haven't given the length setting for any of the above because they all have imherent lengths.
The second field, "Conf" is for a number from 0-9 which users will put in when defining critera. The number will be a guide to their confidence in their ability to judge where that particular stock is headed.
It is not a mistake that there is only one LineStart date. If you drew two lines on a chart in "the real world", there'd be no need for them both to start at the same point left and right. However, it saves us entering, dealing with, a second date if we say that in the computerized version both criterion lines will start at the same left/right distance.
YHi, and YLo are the prices you think the criterion lines should start at. "Y" "y-coordinate. Note the names were done "backwards", they were not HiY and LoY, although that might be more natural. Doing them backwards keeps all fields about "Y" matters together in any alphabetical lists. The same logic was behind the names "SlopeHi" and "SlopeLo".
Enter the following sample data, just to get things started. These numbers might be in use if the system had been up and running since mid 2005, and the date now was 10 Feb 2006, and the user had data on the stocks prices covering all of that period. The chart for Pfizer on 10 February 2006 wasn't giving any clear signs that I can see of where the company was headed, but I've done my best to assign "reasonable" criterion lines. I haven't made up times for the entry of the following criteria... it was just easiest to pretend they were all entered at midnight. (As I am typing this at 00:23, that seemed reasonable. Night owl? Moi?
PFEaCR: Just one record:2Feb06,00:00 2 1Nov05 2800 2500 -300 -400IBMaCR: Just one record:
2Feb06,00:00 8 10Nov05 8900 8000 900 900GOOGaCR: Two records. The first shows the user's critera on 1 October 2005, and the second the criteria that were entered on 6 February 2006
1Oct05,00:00 5 1Sep05 30000 25000 15000 10000 6Feb06,00:00 5 1Jan06 45000 35000 20000 6000
(It is lucky I didn't have the system in place in February 2006... it would have given me "bad advice" on "IBM". What this system, in isolation would have said was "Buy it"... but the price then went lower. Ah, the joys of investing in stocks!
Build the tables just discussed, fill them with the indicated data.
Another table: We will usually be working just with the tickers, but from time to time we will probably want the company's more human- friendly name. There's also the matter of being able to look up the answer to "Was it Sa for Sprint, or Sb? And what was the other stock that once had "S" for its ticker?" This table will be the place to put things that are true for a company, and likely to remain fairly stable. For instance, I will include a field for the company's "sector". (The sector tells us what sort of company it is... Exxon and BP are oil companies, IBM and Hewlett Packard are technology companys.) For the sector, we will use codes, and, as with the CommentType codes, we will use a further table to define what the allowed codes are.
There is a separate tutorial on the setup of StockNames and CodesSectors, and some data entry forms for them. If you are not comfortable with setting up tables, relationships and forms, the tutorial might be worth reading, although if you are only interested in looking at the theory of this project, what follows will probably suffice.
So! Create a table called StockNames...
FieldName FieldType Length --------- --------- ------ Tick Text (fix) 10 Dis Text (fix) 1 Sect Text (fix) 3 Name Text [var] 30
Tick: Ticker
Dis: Disambigufier
Sect: This will hold CODE for the companies sector
Name: The name, in plain English.
Make the first two fields the key for this table. To do that, first select the two rows in the table designer by clicking on the grey box to the left of the "Tick" field, and then, while holding down the CTRL key, click the grey box to the left of the "Dis" field. Then right-click with the pointer still over one of those two grey boxes. Click on "Primary Key".
Fill the table with....
PFE a dru Pfizer IBM a tec International Bus Mach GOOG a tec Google
And now make the table "CodesSectors"....
FieldName FieldType Length --------- --------- ------ SecCd Text(fix) 3 SecDescrip Text[var] 12Make the first field the key field.
Fill the table with....
mis Misc dru Drugs tec Technology
Click here to visit my homepage where you
can explore other areas, such as education, programming, investing.
![]() Page tested for compliance with INDUSTRY (not MS-only) standards, using the free, publicly accessible validator at validator.w3.org
Page tested for compliance with INDUSTRY (not MS-only) standards, using the free, publicly accessible validator at validator.w3.org
....... P a g e . . . E n d s .....